
StreamDiffusion 是一項以開放原始碼發布於 GitHub 的專案,開發者需要下載完整的專案並自行建置系統環境,包括 Python、PyTorch、CUDA 等套件的安裝,才能使用到最初步的功能。如果我們想要將 StreamDiffusion 串接到 TouchDesigner 之類的軟體上,還必須自行開發 NDI、OSC 等連線功能,我們將會在其它文章中來教學。
本文的主題是建構一個有效的 StreamDiffusion 系統建置指南,提供開發者一個能直接依循的方法,來快速建置 StreamDiffusion 於 Windows 平台。
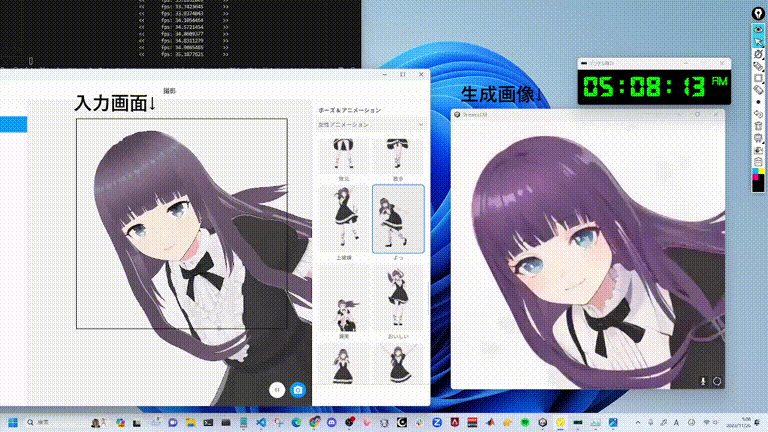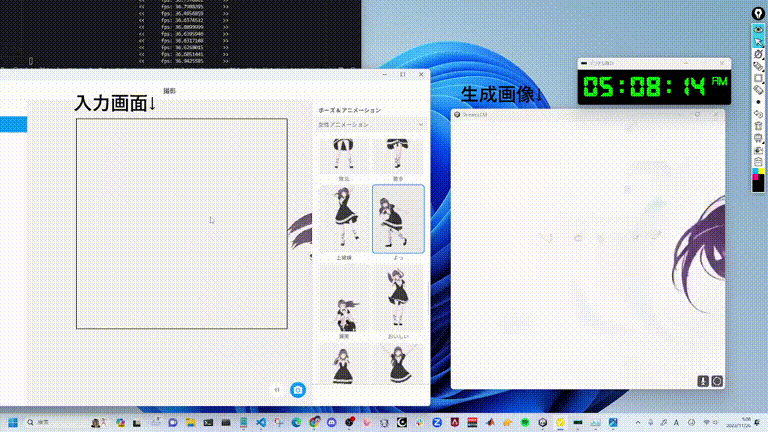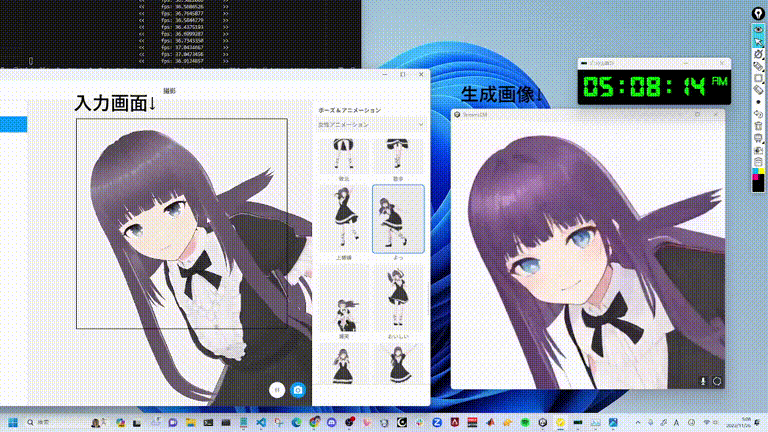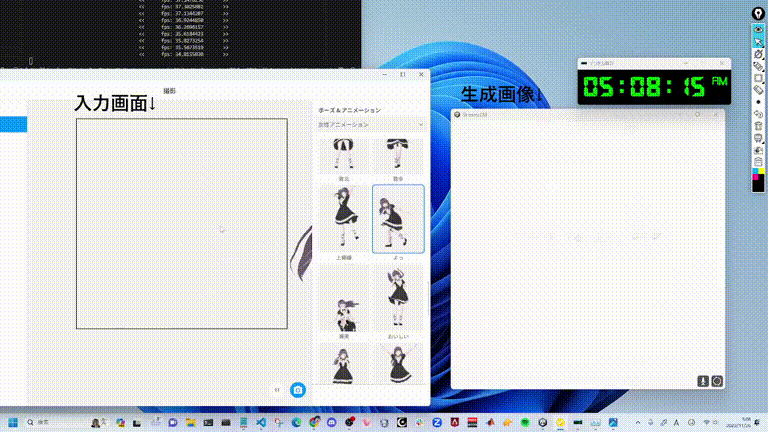 StreamDiffusion 能達到幾乎是即時反應的影像生成效果 (圖片來源:GitHub)
StreamDiffusion 能達到幾乎是即時反應的影像生成效果 (圖片來源:GitHub)
系統需求
本文的目標是將 StreamDiffusion 安裝在 Windows 平台上,並且使用 NVIDIA 顯示卡與 CUDA 技術來進行運算。以 SD Turbo 模型舉例,顯示卡最低的專屬記憶體建議至少要有 8GB,系統記憶體 (RAM) 至少要有 16GB,否則生成速度將大幅下降。
安裝 CUDA 技術核心
CUDA 是一個能讓 AI 模型用來在 NVIDIA 顯示卡上運算的技術,並且正在持續地推出更新。一般來說,新的 CUDA 版本是能夠向下相容使用舊版本的 AI 模型,因此只要安裝的版本沒有過舊,通常不用擔心版本差異問題。
根據 StreamDiffusion 的 Readme 文件說明,最舊支援 CUDA 11.8 版本,請開啟命令提示字元並輸入以下指令來檢查目前已安裝的版本:
1nvcc --version
如果指令執行失敗的話,通常就是指目前電腦中並沒有安裝 CUDA,請前往 NVIDIA 官網的 CUDA Toolkit 專區,並點擊 Download Now 來下載安裝。

特別提醒,CUDA 的安裝選項建議選擇「自訂」,並取消勾選 CUDA 以外的選項,防止安裝失敗。


至此,我們已在 Windows 平台上安裝好 CUDA,StreamDiffusion 將能藉由 CUDA 來驅動 NVIDIA 顯示卡來快速生成影像。
建立 Python 開發環境
近年已有許多方便開發者安裝與管理 Python 的程式,本文將使用其中一款名為「uv」的工具,uv 能解決過去我們用 pip 取得套件時的下載緩慢問題,並且內建了許多自動化工具,能大幅提升 StreamDiffusion 系統的可維護性。
安裝 uv
首先,我們需要在電腦上安裝 uv 工具,請開啟命令提示字元並輸入以下指令:
1powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/0.7.2/install.ps1 | iex"
uv 會被安裝在你的使用者資料夾下的 .local/bin 裡面,我們需要將這個路徑設定到環境變數裡面,請繼續使用剛才開啟的命令提示字元並輸入以下指令:
1SET PATH=%PATH%;%UserProfile%\.local\bin
如果未來不想用 uv 了,開啟檔案總管並前往 %UserProfile%/.local/bin 位置,直接刪除資料夾內的 uv.exe 與 uvx.exe 兩個檔案即可解除安裝。

安裝 Python
StreamDiffusion 使用 Python 3.10 版本,而 3.10 系列的最新版本為 3.10.17,本文使用 uv 來安裝這個版本,請繼續使用剛才開啟的命令提示字元並輸入以下指令:
1uv python install 3.10.17
至此,我們已經在 Windows 平台上安裝好 uv 與 Python,接下來將會圍繞於這兩個工具來建置 StreamDiffusion 系統。
建立 StreamDiffusion 開發環境
本文使用 VS Code 來開發 StreamDiffusion 與 Python 程式,並搭配 uv 工具快速安裝所有的依賴套件。
初始化 Python 專案
StreamDiffusion 使用 Python 來開發,我們需要先初始化好 Python 的專案。
首先,在電腦的任何位置上建立一個新資料夾,並使用 VS Code 開啟。

輸入鍵盤組合鍵「Ctrl + `」來開啟終端機,並輸入以下指令來使用 uv 初始化 Python 專案,並指定專案使用 Python 3.10.17 版本:
1uv init
2uv venv --python 3.10.17
Python 專案初始化後,資料夾內會出現 main.py、pyproject.toml 等檔案,後續我們將著重於 main.py 的開發與 pyproject.toml 的修改。

取得 StreamDiffusion 專案
接下來,我們要將 StreamDiffusion 專案下載下來,並從中提取出我們需要的檔案。
首先,沿用剛才在 VS Code 開啟的終端機,輸入以下指令來下載 StreamDiffusion:
1git clone https://github.com/cumulo-autumn/StreamDiffusion.git
完成下載後,專案內會多出一個 StreamDiffusion 資料夾,裡面是 StreamDiffusion 的主程式、範例程式和說明文件。

本文的重點在於要將 StreamDiffusion 應用到我們自己的系統,只需要它的主程式。因此,請繼續使用 VS Code 的終端機,依序輸入以下指令來將主程式提取出來,並刪除多餘的資料:
1powershell Rename-Item -Path "StreamDiffusion" "StreamDiffusion_Bak"
2powershell Move-Item -Path "StreamDiffusion_Bak\src\streamdiffusion" "streamdiffusion"
3powershell Move-Item -Path "StreamDiffusion_Bak\utils" "utils"
4powershell Remove-Item -Recurse -Force "StreamDiffusion_Bak"
最後,我們的 Python 專案內的「StreamDiffusion」資料夾已刪除 (有大寫英文),取而代之的是全小寫英文的「streamdiffusion」和「utils」資料夾,這兩個資料夾內的程式是 StreamDiffusion 的核心程式。

安裝 StreamDiffusion 依賴套件
StreamDiffusion 需要許多套件的配合才能生成影像,我們需要手動來安裝它們。
首先,經過我們的測試,StreamDiffusion 相容於 PyTorch 的 CUDA 12.8 版本,本文將使用該版本來建置環境。

因為我們是用 uv 來管理 Python 專案,因此本文不使用過去所用的 pip install 指令,而是以 uv 提供的指令來取代。PyTorch 的 CUDA 12.8 版本需要從 PyTorch 官方提供的來源來取得該套件,請編輯 pyproject.toml 檔案,將以下內容複製貼上到檔案現有資料的後面,來確保 uv 之後會從指定的來源來下載 PyTorch。
1[[tool.uv.index]]
2name = "pytorch-cu128"
3url = "https://download.pytorch.org/whl/cu128"
4explicit = true
5
6[tool.uv.sources]
7torch = [
8 { index = "pytorch-cu128", marker = "sys_platform == 'win32'" },
9]
10torchvision = [
11 { index = "pytorch-cu128", marker = "sys_platform == 'win32'" },
12]
請參考下圖,複製的內容請貼上到現有資料的後面。

接下來我們要取得所有 StreamDiffusion 依賴的 Python 套件,請繼續編輯 pyproject.toml 檔案,並複製以下內容並取代檔案內 dependencies 的資料:
1dependencies = [
2 "diffusers==0.29.0",
3 "pywin32>=310",
4 "six>=1.17.0",
5 "torch",
6 "torchvision",
7 "transformers>=4.51.3",
8 "xformers>=0.0.30",
9 "accelerate",
10 "fire",
11 "omegaconf",
12 "cuda-python",
13 "onnx",
14 "onnxruntime",
15 "protobuf",
16 "colored"
17]
貼上的位置請參考下圖反白處,當我們在 pyproject.toml 的 dependencies 中加入這些套件設定,接下來就能讓 uv 自動的幫我們安裝好。

最後請使用 VS Code 的終端機,輸入以下指令來讓 uv 幫我們安裝所有 StreamDiffusion 依賴的套件,下載套件需要一點時間。
1uv sync
操作到這裡,我們已經將 StreamDiffusion 的開發環境建置完畢。在本文的最後,我們將會以一張參考圖片和一組提示詞來測試 StreamDiffusion 的圖生圖 (Img2Img),也以單獨使用提示詞來測試文生圖 (Txt2Img) 功能。
圖生圖功能測試
StreamDiffusion 的圖片生圖片功能需要我們提供一張參考圖和一組提示詞,請自行準備一張圖片複製到 Python 專案裡面,並取名為 image.png。

接下來我們要寫一段程式碼,讓 StreamDiffusion 讀取我們準備的 image.png,再以「cat, detailed, fantasy, 8k」提示詞和 SD Turbo 模型來生成影像,最後儲存為 result.png。
請編輯 main.py,刪除裡面的所有資料,並複製貼上以下程式碼:
1from utils.wrapper import StreamDiffusionWrapper
2
3def main():
4 # 初始化模型
5 stream = StreamDiffusionWrapper(
6 model_id_or_path="stabilityai/sd-turbo",
7 t_index_list=[24, 32],
8 width=512,
9 height=512,
10 acceleration="xformers",
11 mode="img2img"
12 )
13 stream.prepare(prompt="cat, detailed, fantasy, 8k")
14
15 # 影像前處理
16 input = stream.preprocess_image("image.png")
17
18 # 模型熱機
19 for _ in range(stream.batch_size - 1):
20 stream(image=input)
21
22 # 生成影像
23 output = stream(image=input)
24 output.save("result.png")
25
26if __name__ == "__main__":
27 main()
最後請使用 VS Code 的終端機,輸入以下指令來執行 main.py:
1uv run main.py
第一次執行 main.py 時,StreamDiffusion 會自動下載 SD Turbo 模型,會需要一點時間。當生成影像後,Python 專案內會多出一個 result.png,打開該檔案後即可看到圖片生圖片的影像生成結果。

文生圖功能測試
文字生圖片僅需準備一組提示詞就能生成影像,請編輯 main.py,並複製貼上以下程式碼:
1from utils.wrapper import StreamDiffusionWrapper
2
3def main():
4 # 初始化模型
5 stream = StreamDiffusionWrapper(
6 model_id_or_path="stabilityai/sd-turbo",
7 t_index_list=[0, 24, 32],
8 width=512,
9 height=512,
10 cfg_type="none",
11 acceleration="xformers",
12 mode="txt2img"
13 )
14 stream.prepare(prompt="cat, detailed, fantasy, 8k")
15
16 # 模型熱機
17 for _ in range(stream.batch_size - 1):
18 stream()
19
20 # 生成影像
21 output = stream()
22 output.save("result.png")
23
24if __name__ == "__main__":
25 main()
一樣請使用 VS Code 的終端機,輸入以下指令來執行 main.py:
1uv run main.py
生成結束後開啟 Python 專案內的 result.png,即可看到文字生圖片的影像生成結果。

結語
完成本文的進度後,我們已經順利讓 StreamDiffusion 的核心功能在 Windows 平台上執行。現在只能透過修改專案內的圖片或提示詞來影響生成結果,接下來我們將開始為這一套系統開發從外部控制提示詞和輸入影像,並做到即時傳輸的效果。